Instrukcja
Wprowadzenie
Dane korpusu są dostępne w wyszukiwarce segmentów (w przybliżeniu: słów), w której teksty korpusu mogą być przeszukiwane za pomocą elastycznego języka zapytań uwzględniającego wielowarstwowy opis lingwistyczny, a wynikiem tego wyszukiwania są słowa prezentowane w kontekście, w którym występują.
Wyszukiwanie segmentów
Wyszukiwanie segmentów polega w najprostszym trybie na wprowadzeniu zapytania, które chcemy wykonać, a następnie wciśnięciu przycisku „Wyszukaj”. Opis języka zapytań zamieszczamy na końcu tego dokumentu; najprostsze zapytanie o wszystkie segmenty składa się z pustego zestawu nawiasów kwadratowych []. Wyniki można ponadto ograniczać metadanymi (np. do tekstów określonego typu) podając je w panelu rozwijanym po naciśnięciu przycisku „Metadane”.
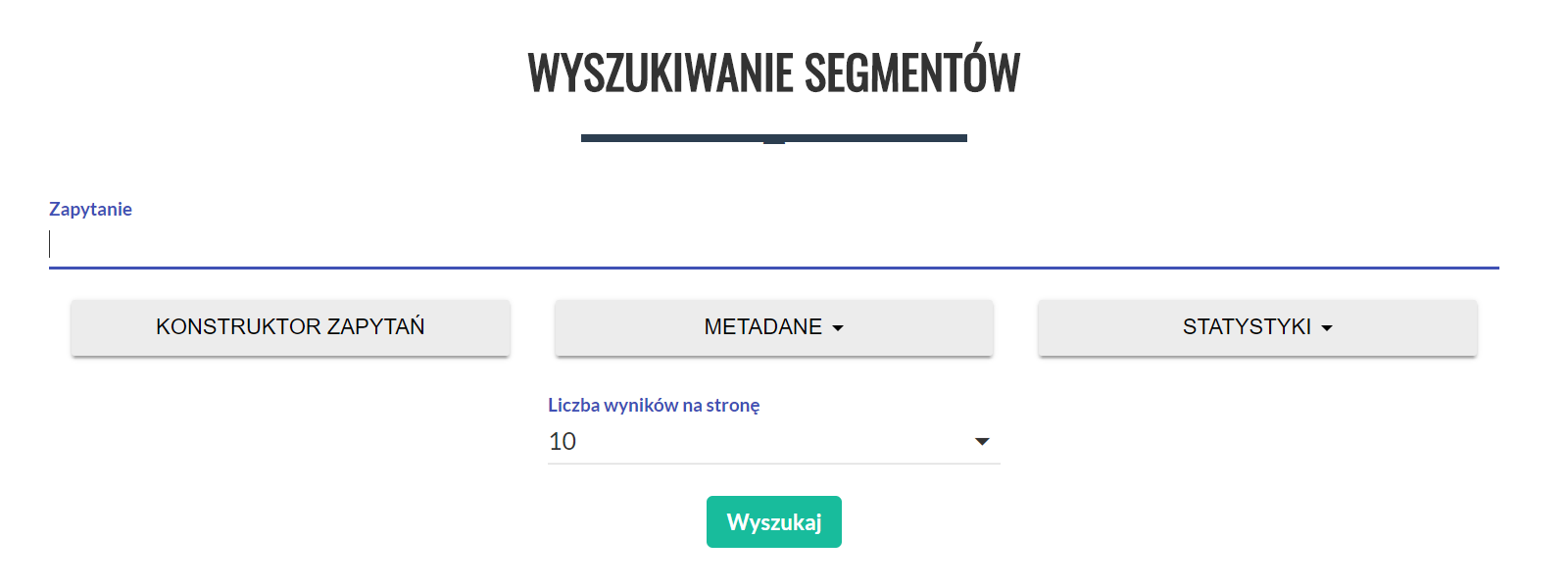
Po wykonaniu zapytania zostaniemy przeniesieni do strony z wynikami, które możemy przeglądać. Dodatkowo możemy wyświetlić dodatkowe informacje o kontekście znalezionego wyniku, klikając na niego lub pobrać całą listę wyników w formie pliku CSV.

Konstruktor zapytań
Zapytania można tworzyć z pomocą graficznego konstruktora wybierając pożądane własności ciągu segmentów. Grafika ilustruje budowę zapytania wyszukującego w korpusie frazy przyimkowe z przyimkiem celownikowym składające się z przyimka i rzeczownika.
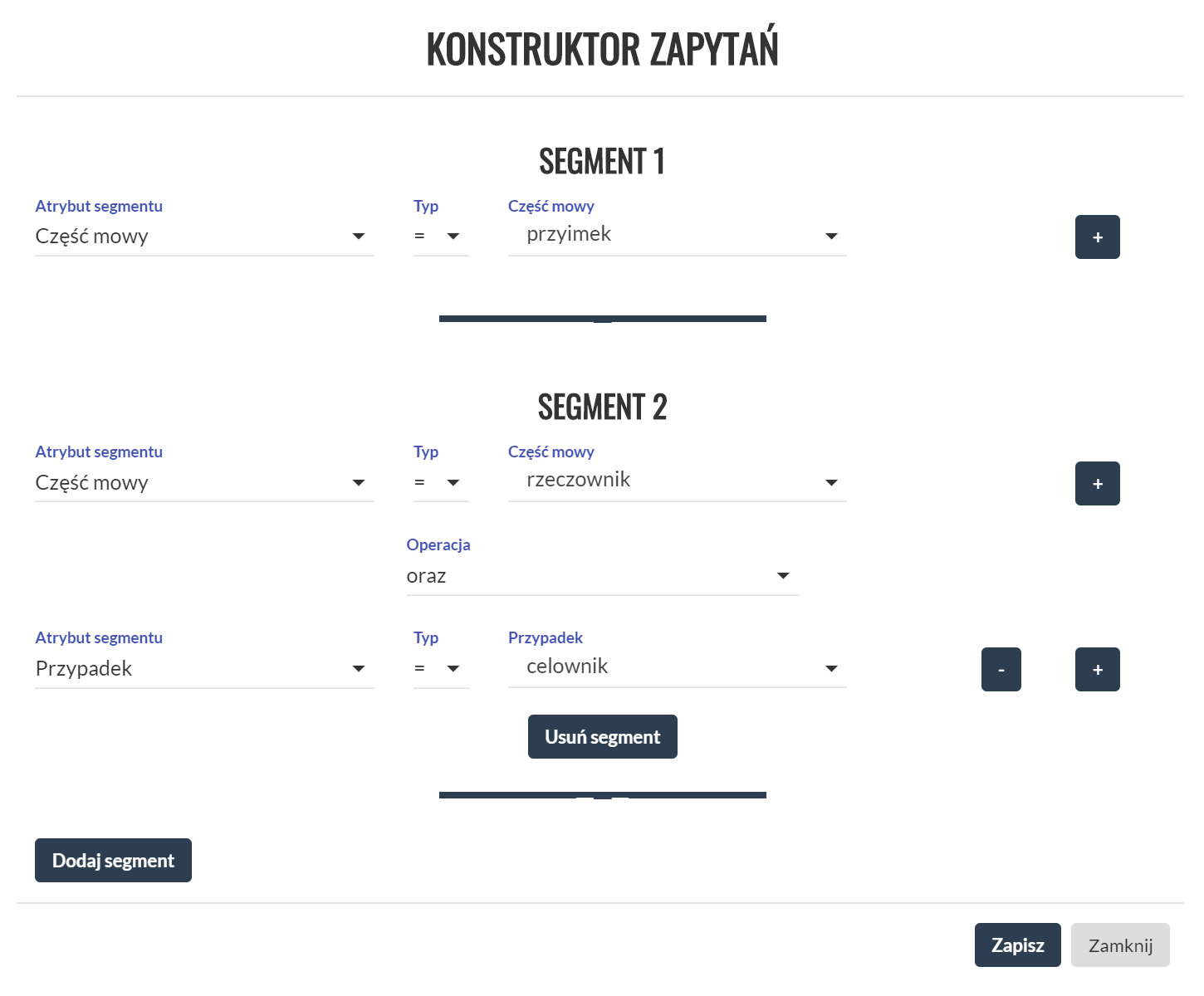
Stworzone zapytanie jest tłumaczone na język wyszukiwarki (dla naszego przykładu ma postać [pos="prep"][pos="subst"&case="dat"]), a następnie uruchamiane (jego wynikiem jest lista prezentowana wyżej).
Opis lingwistyczny
Opis lingwistyczny korpusu został przejęty wprost z Narodowego Korpusu Języka Polskiego. Teksty korpusu anotowane są automatycznymi narzędziami analizy lingwistycznej na kilku poziomach: segmentacji na wypowiedzi, zdania i uogólnione słowa (segmenty) oraz morfoskładni, natomiast ręcznie — na poziomie opisu relacji referencyjnych i pomocniczych.
Segmentami są zwykle słowa tekstowe (ciągi liter ograniczone spacjami lub znakami interpunkcyjnymi), w niektórych wypadkach dodatkowo rozdzielone na części zgodnie z ich podstrukturą morfoskładniową. Przypadki takiego podziału obejmują np. formy aglutynacyjne leksemu BYĆ (p. np. łgał|eś, długo|śmy, tak|em), partykuły by, -ż(e) i -li (przyszedł|by, napisała|by|m, chodź|że, potrzebował|że|by|ś, niechaj|że|ż, znasz|li), poprzyimkowe nieakcentowane formy zaimka -ń (do|ń, ze|ń) czy niektóre słowa zawierajace łącznik (polsko|-|niemiecki, Kowalska|-|Nowakowska, Jean|-|Pierre) — p. rozdział 6.2.2 z książki NKJP. Samodzielnymi segmentami są także znaki interpunkcyjne.
Warstwa morfoskładniowa przypisuje segmentom znaczniki określające ich formę podstawową (lemat), klasę gramatyczną oraz odpowiednie wartości kategorii gramatycznych. Repertuar klas i kategorii gramatycznych oparty jest na zbiorze klas i kategorii (tagsecie) stosowanym w analizatorze morfologicznym Morfeusz i opisanym w ściągawce do NKJP.
Język zapytań
Składnia zapytań wyszukiwarki jest zbliżona do składni wyszukiwarki Poliqarp wykorzystywanej m.in. do przeszukiwania NKJP.
Zapytania o segmenty i formy podstawowe wpisujemy w nawiasach kwadratowych według schematu: [atrybut="wartość"] (podając wartość w cudzysłowie). W najprostszych pytaniach o kształt tekstowy segmentu atrybutem będzie orth, a jego wartością — poszukiwany ciąg liter, np. [orth="niepodległość"] (wielkość liter ma znaczenie). Inne często używane atrybuty morfoskładniowe to number, case, gender, person, degree, aspect czy negation (nazwy klas i kategorii gramatycznych najlepiej sprawdzać używając konstruktora zapytań lub angielskiej wersji ściągawki do NKJP).
Aby znaleźć wszystkie formy fleksyjne segmentu, należy użyć atrybutu base, np. [base="Polska"]. Wartością tego atrybutu jest forma podstawowa szukanego fleksemu, a zatem mianownik liczby pojedynczej dla rzeczowników czy bezokolicznik dla wszystkich fleksemów czasownikowych.
W zapytaniach o segmenty mogą wystąpić standardowe wyrażenia regularne z użyciem symboli:
- kropki zastępującej dowolny znak — np. wyrażenie bez. odpowiada segmentom beza, bezy, bezą itp., ale nie bez czy bezami,
- znaku zapytania oznaczającego opcjonalność poprzedniego znaku — wyrażenie beza? odpowiada segmentom bez lub beza,
- gwiazdki oznaczającej dowolną (także zerową) liczbę wystąpień znaku lub wyrażenia bezpośrednio przed nią — Ala.* odpowiada segmentom Ala i Alaska,
- nawiasów klamrowych oznaczających określoną liczbę wystąpień znaku lub wyrażenia poprzedzającego, np. tra(la){2,3} odpowiada segmentom tralala i tralalala.
Jeśli chcemy wyszukać kilka sąsiadujących ze sobą segmentów lub form podstawowych, każdą pozycję zapisujemy w oddzielnych nawiasach kwadratowych, czyli np. zapytanie [base="nasz"][base="kraj"] da w wyniku fragmenty tekstów zawierające wyrażenia „naszego kraju, „naszym kraju” itd.
Oznaczając za pomocą pustych nawiasów kwadratowych dowolny segment, możemy znaleźć formy, które nie sąsiadują ze sobą bezpośrednio, np. zapytanie: [base="do"][]{1,2}[base="śmierć"] odnajdzie w korpusie teksty zawierające ciągi do swej przedwczesnej śmierci czy do chwili śmierci.
Atrybuty określane w zapytaniach można łączyć używając operatorów koniunkcji &, alternatywy | i negacji !. Zapytanie [orth="stara" & !pos="adj"] wyświetli zatem wszystkie wystąpienia słowa stara, które nie są przymiotnikami (np. „Łukasz zawsze stara się być przy panu Zdzisiu poważny”).
Zapytania o wzmianki zadajemy w nawiasach kątowych: <mention/>. Najprostszy sposób łączenia anotacji z różnych warstw to użycie filtra containing, np. wzmianki w dopełniaczu wyszukamy uruchamiając zapytanie <mention/> containing [case="gen"]. Zapytania o klastry (<coref/>) dają w wyniku wyrażenia dominujące klastrów. Można je przeszukiwać podając treść wyrażenia dominującego jako argument filtra coref, np. <coref="on"> da w wyniku listę wzmianek, dla których za wyrażenie dominujące został uznany zaimek „on”. Typy wzmianek podajemy w dodatkowym atrybucie, np. <coref.type="ident"/>; wartości dla pozostałych relacji podajemy w poniższej tabeli:
| referencja bezpośrednia | — | ident |
| agregacja | — | indirect_aggregation |
| kompozycja | — | indirect_composition |
| kategorialność | — | excluding_ios |
| anafora związana | — | indirect_bound |
| inna relacja pośrednia | — | indirect_other |
| metareferencja | — | supporting_metareference |
| porównanie | — | supporting_comparison |
| predykat | — | supporting_predicative |
| inna relacje wspierająca | — | supporting_other |
| kontrast | — | excluding_contrast |
| polisemia | — | excluding_polysemy |
| inna relacja wykluczająca | — | excluding_other |
Dodane elipsy najłatwiej znaleźć wyszukując segment Ø (albo [orth="Ø"]).
Podziękowania
Instrukcja powstała na bazie wcześniejszych dokumentów opisujących sposób użycia wyszukiwarki MTAS i zestaw znaczników Narodowego Korpusu Języka Polskiego, w szczególności Ściągawki do Narodowego Korpusu Języka Polskiego autorstwa Adama Przepiórkowskiego, Aleksandra Buczyńskiego i Jakuba Wilka, Instrukcji korzystania z wyszukiwarki do Elektronicznego Korpusu Tekstów Polskich z XVII i XVIII wieku (do 1772 r.) Włodzimierza Gruszczyńskiego i Renaty Bronikowskiej oraz Instrukcja korzystania z wyszukiwarki korpusu tekstów polskich z lat 1830-1918 i Instrukcji użytkownika Korpusomatu Witolda Kierasia.